






Кто и зачем проводит аудит коммерческих факторов?
Представим себе такую ситуацию (а многим, мы уверены, и представлять не придется)… У вас есть сайт: интернет-магазин или сайт услуг. Вроде вы на нем разместили и информацию, и цены, и страницы продумали, описали всё подробненько, заказали тексты у хороших копирайтеров, устранили технические проблемы… одним словом, поработали над сайтом от души. А сайт всё равно ранжируется хуже, чем конкуренты. И пользователи заходят и покупают как-то неохотно. Вы думаете: что я не так делаю? Почему первые позиции в выдаче все еще занимают другие? В чем их преимущество?
Проводите аудит коммерческих факторов — и вот в ваших руках целый список того, что нужно изменить, чтобы стать лучше. А вы даже не ожидали, что те самые отзывы о товаре, которые вы считали “бесполезными”, или скидки, которые вы не хотели делать, напрямую влияют на позиции в вашей нише.
Или другой пример. Вы находитесь на этапе создания интернет-магазина или сайта услуг. Хочется сделать изначально как минимум не хуже, чем конкуренты, не так ли? И одно дело — знать среднюю цену в своем сегменте, и совсем другое — обнаружить, что лучше ранжируются сайты с более высокой средней ценой. Или что у конкурентов с видимостью в топ-3 обязательно есть видео в товарных карточках.
Проводите все тот же анализ коммерческих факторов конкурентов — и вот он, список рекомендаций, как и что оформить, чтобы сразу “понравиться” поисковой системе и пользователям. Лучше продумать сразу и сделать качественно, чем потом бесконечно переделывать, не правда ли?
А что, если мы скажем, что такую проверку может провести любой из вас?
Технически это совсем несложно, финансово — более чем доступно.
Вам понадобится: Netpeak Spider (достаточно пробной бесплатной версии на 7 дней), XPath Helper Wizard (бесплатно), Excel и ваш любимый браузер. Для семантики и отбора по видимости можно использовать Key Collector (платный), но если его у вас нет, можно воспользоваться бесплатной альтернативой http://www.xn--90abjwpbr.xn--p1ai/.
Друзья, маленький дисклеймер. В статье мы рассказываем про то, как парсить сайты с помощью Нетпик. Но не обязательно пользоваться именно Нетпиком, для выполнения описанных в статье действий подойдет любой софт, умеющий парсить по XPath. Просто у себя в студии мы используем этот инструмент каждый день, все наши специалисты работают на нем, именно поэтому в статье мы используем скриншоты из него.
Ну а если вы решили купить Нетпик после этой статьи, воспользуйтесь нашим промокодом From-Ant-Team-With-Love, он даст вам скидку 10%, а нам за это будет небольшой бонус.
Также понадобится немного свободного времени и, конечно, голова (для подумать).
Отобрали конкурентов по видимости
Наши коллеги из команды https://ozhgibesov.net/ записали отличное видео (тайминг 11:06 — 12:19) о том, как отобрать конкурентов по видимости. Мы не будем дублировать эту информацию, а предлагаем вам ознакомиться с ней напрямую. Конечно, следует понимать, что для поиска конкурентов нам потребуется семантическое ядро или некая выборка ключевых слов для анализа.
На видео используется платный софт, в частности — КейКоллектор. Безусловно, его можно заменить бесплатным — “Слово*б” и 7-дневной триальной версией NetPeak Чекер.
Слово*б вам позволит собрать ключевые слова и их частотности, а “Чекер” — пропарсить поисковую выдачу Яндекс или Гугл по отобранным ключевым словам, а также определить их позиции. Собранные данные о позициях в поисковой выдаче являются фундаментальными для основной таблицы анализа конкурентов. Наложение видимости конкурентов происходит на каждом из графиков, который в последующем используется для построения отчета. Пример графика с наложением видимости представлен на рисунке 1.
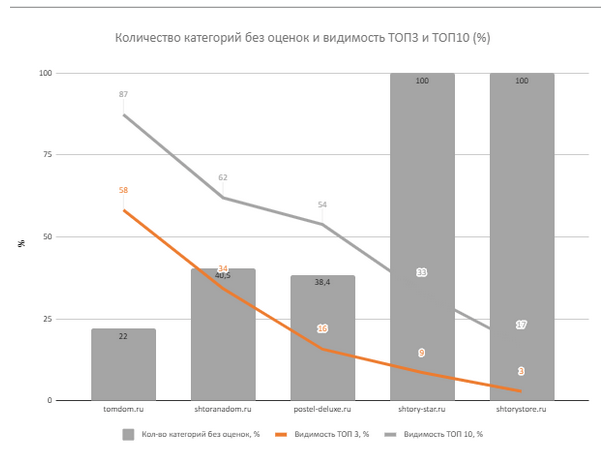
Рисунок 1 — Пример наложения видимости конкурентов количества категорий без отзывов (оценок)
Обратите внимание! Парсинг частотностей “Слово*бом” и поисковой выдачи Нетпиком требует аккаунтов Яндекса и прокси. Если вы и вправду решили профессионально заниматься парсингом, все же мы рекомендуем рассмотреть покупку КейКоллектора.
Отобрали конкурентов по тематичности и размеру
Недостаточно отобрать конкурентов по видимости, нужно еще тематическое соответствие. То есть мы не будем сравнивать агрегаторы и информационники с интернет-магазинами и сайтами услуг. Необходимо на этом этапе выкинуть всех тематически неподходящих.
Также мы берем для сравнения только те сайты, которые похожи по размеру, то есть по количеству страниц в индексе ПС. Сравнивать сайты, размеры которых сильно разнятся (например, 1к страниц и 100к страниц), в данном случае не имеет смысла.
Узнать количество страниц в индексе поисковой системы очень просто.
Смотрим через оператор site: количество страниц в индексе того поисковика, по которому сравнивали видимость.
Вот так: site:domain.ru
Примеры запросов в Яндекс и Google:


Рисунок 2 — Примеры запросов в Яндекс и Google
Сводная таблица будет служить основой нашего анализа. Сюда мы соберём все полученные в дальнейшем результаты и на её основе будем описывать закономерности и давать рекомендации.
Заносим туда названия выбранных конкурентов, наш сайт (если надо), видимость и количество страниц в индексе.
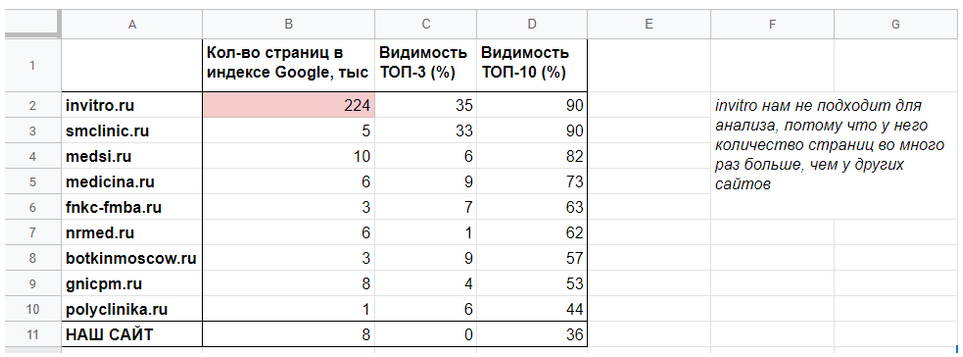
Рисунок 3 — Сводная таблица
Решили: будем парсить весь сайт или только какие-то разделы
На этом этапе необходимо определиться, будем мы парсить сайты целиком или частично. Как это решить?
Сайты услуг обычно не очень большие и их можно спарсить полностью. Но не всегда. Например, invitro.ru построен как интернет-магазин, хотя предоставляет услуги. У него очень много страниц (223 тыс. в индексе Гугла). Сайты услуг такого масштаба можно парсить частично, то есть только один или несколько разделов.
Или если мы хотим проанализировать какое-то конкретное направление услуг, например, ортодонтию, а сайты конкурентов содержат еще какие-то неинтересные нам спектры услуг, например, офтальмологию и хирургию, то мы также можем парсить только нужный раздел.
Для интернет-магазинов чаще подходит частичный анализ одного или нескольких разделов. У них бывает настолько много страниц, что полный парсинг не оправдан по времени или вообще невозможен, например, если cms бесконечно генерирует страницы.
Или, как в описанном выше примере для сайта услуг, нас не интересуют другие направления, кроме конкретной категории. Пример: profhairsmag.ru продает много разной косметики и прочих товаров, но нас могут интересовать только гель-лаки.
Итак, мы оценили временные затраты и тематическое соответствие сайтов и выбрали подходящий метод.
Просмотрели, что будем парсить
Парсить можно всё, что повторяется у конкурентов и что можно выразить в числовых значениях. Проще говоря, парсить можно любые количества — символов, блоков, картинок, страниц, оценок и т.д.
Проведя несколько анализов коммерческих факторов конкурентов в разных тематиках, мы составили для себя небольшой Чек-лист: Что сравнивать у конкурентов. Конечно же, он очень общий, и для каждой тематики необходимо просматривать страницы вручную и думать, что еще можно сравнить.
Любой фактор может в итоге оказаться коррелирующим с видимостью. Или не оказаться, но отсутствие результата в нашем случае — тоже результат: в таком случае мы просто поймем, что этот фактор, скорее всего, не является решающим для данной тематики.
1. Для интернет-магазина: категории и товарные карточки (что именно в них)
Пример категории: https://tomdom.ru/catalog/tulles/
Пример товара: https://tomdom.ru/catalog/tulles/velo-bel.html
2. Для сайта услуг: категории и карточки услуг (что именно в них), информационную часть и, скорее всего, что-то еще можно посмотреть вручную
Пример услуги: https://www.alfazdrav.ru/uslugi/oftalmolog/
Пример инфо статьи: https://www.smclinic.ru/press-centr/articles/
Внесли все пункты в созданную ранее табличку.
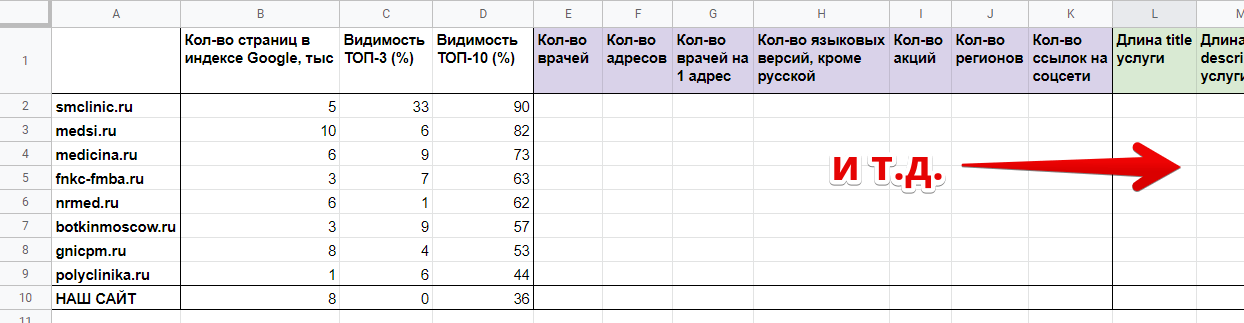
Рисунок 4 — Сводная таблица
Составили правила XPath
Теперь нам нужно научиться использовать XPath. Что это такое?
XPath — язык запросов к элементам XML или XHTML документа. Фактически он описывает путь до нужного элемента(ов) на странице. С его помощью можно посчитать элементы, получить их внутренний код, текстовое содержимое или boolean — факт наличия или отсутствия элемента.
Путь до элемента может быть полным (абсолютным):
/html/body/div[3]/div[2]/div/div/div[3]/form/table/tbody/tr[1]/td[2]/input
или относительным:
//*[@id=»content-in»]//input
Чаще всего мы используем относительный.
Плагин XPath Helper Wizard нужен для упрощения составления XPath запросов
Зажимаем Shift и наводим курсор на нужный элемент. В поле наверху автоматически генерируется запрос к выделенному элементу, но там же можно править и составлять запросы вручную. Важно, что работает плагин только при включенном JS.

Рисунок 5 — Работа плагина XPath Helper Wizard
Особые случаи
Иногда (часто при парсинге изображений или видео) мы сталкиваемся с тем, что элемент подгружается с помощью JS. В таком случае необходимо смотреть исходный код страницы с выключенным JS и составлять XPath именно для тех элементов, которые грузятся без него.
Пример: https://nail-mania.ru/gel-lak-indi-laque-9-ml-n3637/
Здесь карусель изображений в товарной карточке создана с помощью JS.
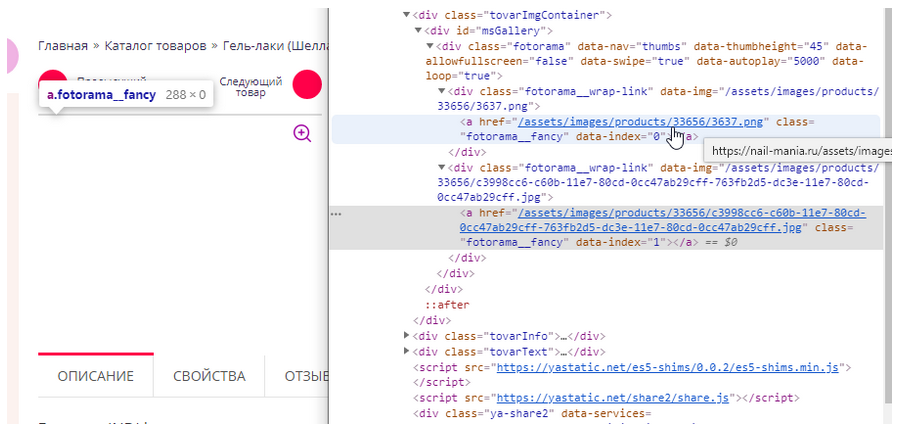
Рисунок 6 — Карусель изображений в товарной карточке создана с помощью JS
Выключаем JS на странице и перезагружаем её.
В коде страницы без JS видим, какие элементы отображаются теперь. Парсить будем по запросу //a[contains(@class, ‘fotorama__fancy’)] .
Еще пример: https://postel-deluxe.ru/shtori.html
Мы хотим спарсить рейтинг товаров, но он выведен как процент от width звездочек.
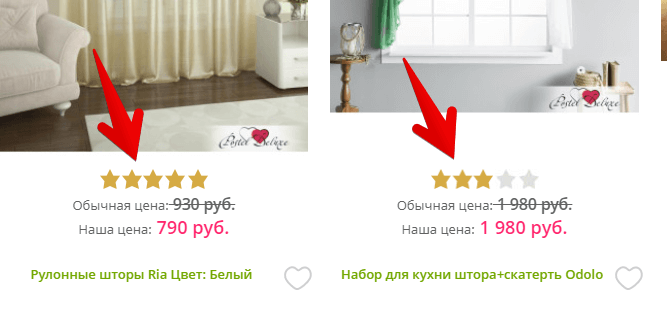

Рисунок 7 — Парсинг рейтинга товаров
Парсим //div[contains(@class, ‘rating-box’)] как внутренний HTML-код и с помощью текстовых фильтров выделяем нужные значения.
Пример выгрузки парсинга внутреннего HTML-кода:
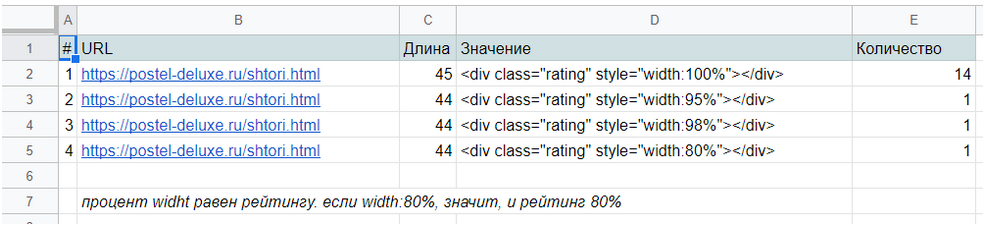
Рисунок 8 — Пример выгрузки парсинга внутреннего HTML-кода
Проверили правила на нескольких страницах в Netpeak Spider
Часто бывает, что запрос в плагине работает, а в Netpeak Spider — нет, и наоборот. Поэтому составленные запросы добавляем в Нетпик и проверяем на нескольких урлах. Дорабатываем нерабочие при необходимости и только после этого будем парсить всё.
Настройка Netpeak Spider на парсинг XPath
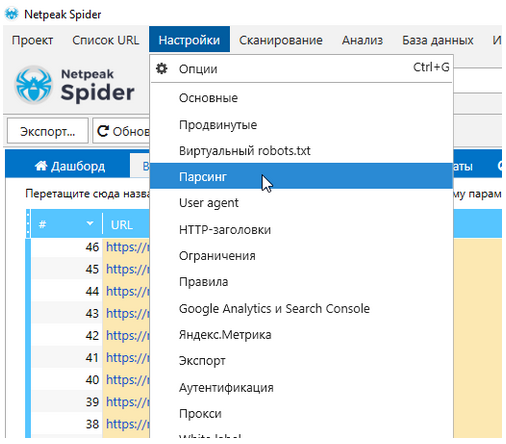
Рисунок 9 — Настройка Netpeak Spider
Подготовим файл, где напишем:
- что будем парсить
- запросы для парсинга
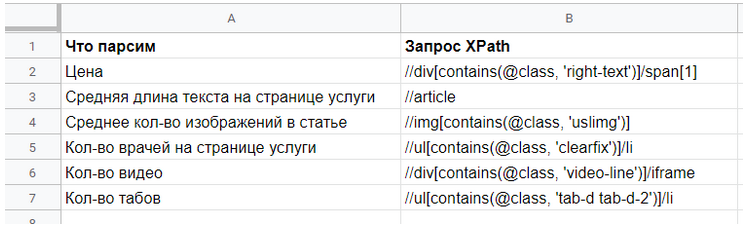
Рисунок 10 — Файл запросов
В настройках парсинга укажем все подготовленные правила, не забываем выставить на XPath. Обязательно подпишем их, желательно так же, как в подготовленном файле — это позволит не запутаться. Это особенно важно, когда парсится одновременно много характеристик нескольких сайтов и потом по выгрузке сразу не видно, где какой результат.
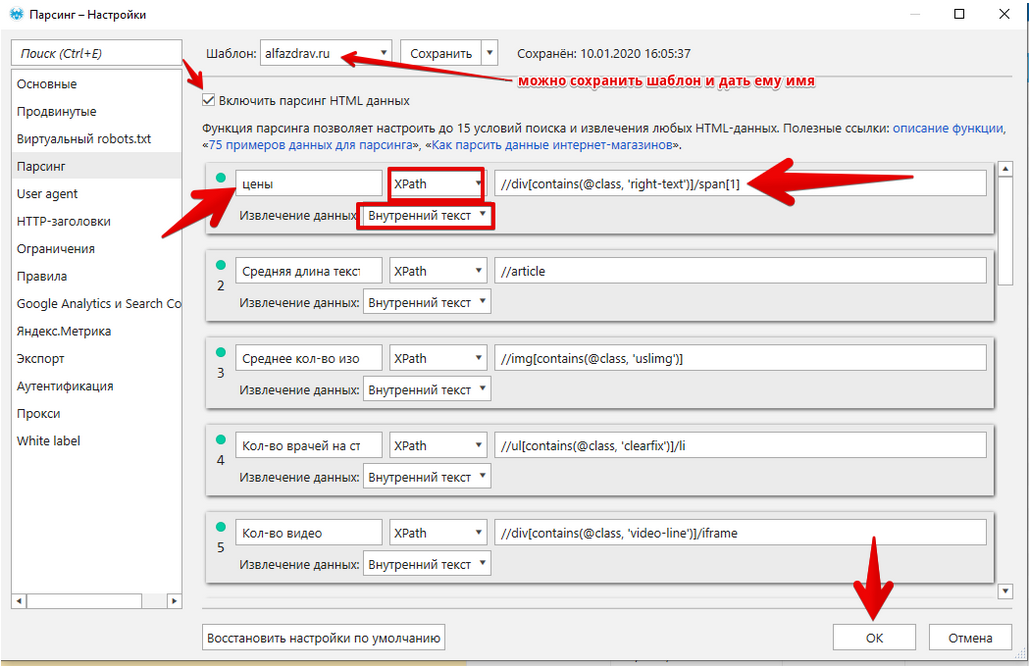
Рисунок 11 — Настройки парсинга
При выборе XPath появляется выпадающий список “Извлечение данных”. Рассмотрим предложенные варианты:
Пример <a href=”https://example.com/”><b>Текст ссылки</b></a>, обращаемся к эл-ту а
- Внутренний текст значит, что будет извлекаться только текст элемента и всех дочерних элементов, исключая HTML-теги.
Текст ссылки
- Внутренний HTML-код значит, что будет извлекаться всё содержимое элемента
<b>Текст ссылки</b>
- Весь HTML-элемент значит, что будет извлекаться весь HTML-код
<a href=”https://example.com/”><b>Текст ссылки</b></a>
- Значение атрибута — здесь можно указать, какой именно атрибут необходимо извлекать. Например, при указании «href» в ссылке «а» будет извлекаться чистая ссылка
Нам также будут важны такие значения, как длина title, длина description, длина h1, для некоторых проектов могут понадобиться заголовки h2-h6. Выставляем нужные галочки. Обязательно ставим Код ответа сервера, чтобы в нашу статистику не попали битые страницы и чтобы сразу заметить, если пойдут 503 ответы.

Рисунок 12 — Параметры парсинга
Подумали, как разделить урлы категорий, товаров/услуг и инфо
В настройках Нетпика ограничено количество строк для XPath запросов. Скорее всего, у нас не получится парсить одновременно и товары (услуги), и категории, к тому же это займет больше времени. Имеет смысл подготовить списки урлов отдельно для категорий, статей, услуг и товаров.
Нам очень повезет, если в Sitemap идет автоматическое разделение на товары и категории, пример: https://tomdom.ru/sitemap_index.xml. Единственный минус — мы не сможем легко разделить, к какой категории какой товар относится, но это не всегда и нужно.
Выгрузить ссылки из сайтмап можно при помощи Нетпик (Список URL — Загрузить из Sitemap). Сюда копируем адрес карты сайта и запускаем парсинг ссылок. После этого можно сразу запустить парсинг или сохранить ссылки в документ.

Рисунок 13 — Выгрузка ссылок из сайтмап
Также нам повезет, если у сайта хорошая структура ЧПУ, по которой видно, где товар (услуга), где инфо, а где категория. Пример:
- https://www.alfazdrav.ru/uslugi/allergologimmunolog/ — услуга
- https://www.alfazdrav.ru/zabolevania/allergicheskie-zabolevaniya/ — инфо
При отсутствии сайтмап на таких сайтах можно спарсить весь сайт (урл, код ответа и content-type) и разделить урлы быстрым фильтром.
В самом плохом варианте, если у сайта нет разделенного сайтмап и удобных ЧПУ, приходится парсить весь сайт с использованием XPath элементов, которые точно всегда есть на страницах одного типа и точно отсутствуют на всех других (например, товарные табы, которые используются только в товарной карточке). Тогда в итоге мы получаем файл, в котором сразу видно деление на заданные категории:
Пример деления категорий и товаров
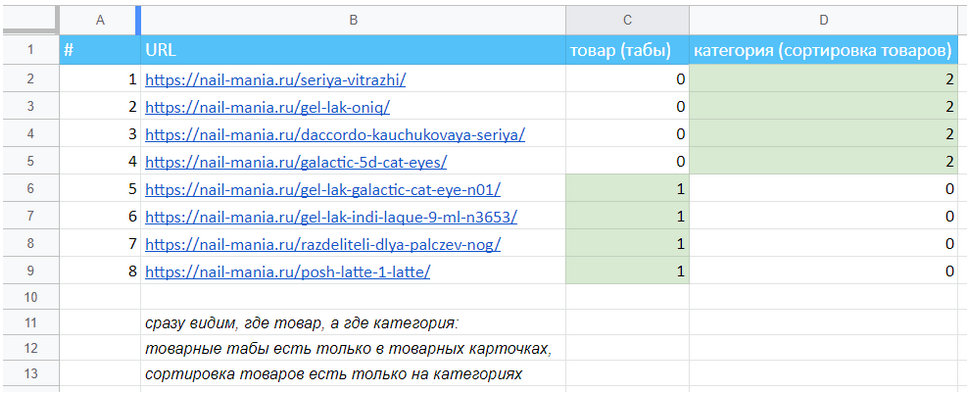
Рисунок 14 — Пример деления категорий и товаров
Подготовили списки урлов для парсинга
Настроили при необходимости прокси, количество потоков и задержку между запросами. У нас уже загружены 10 рабочих прокси, количество потоков выставлено равным количеству прокси и задержки между запросами нет.

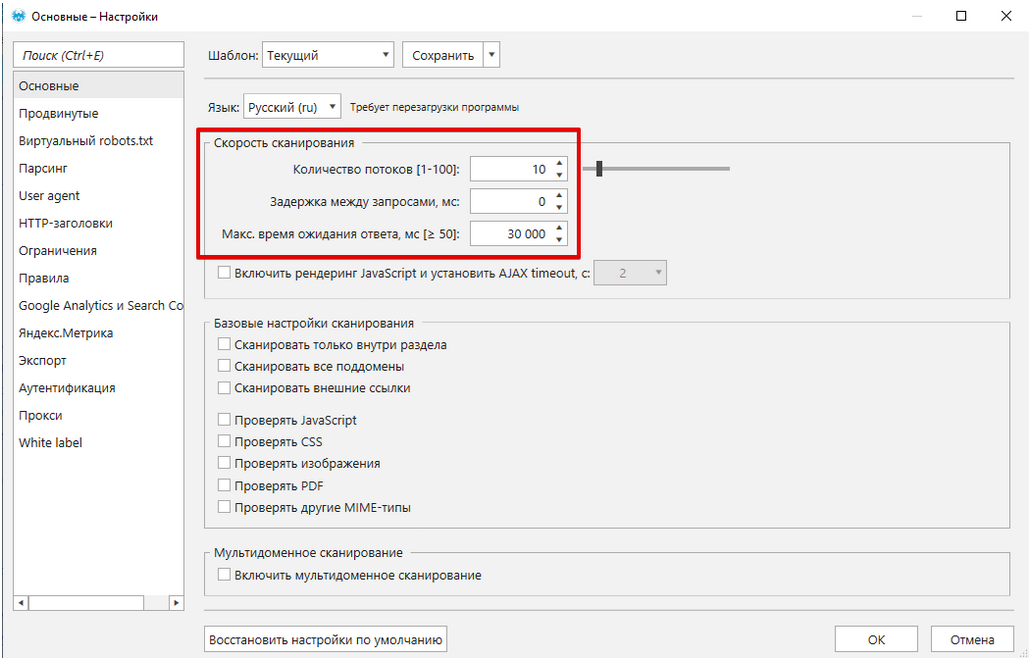
Рисунок 15 — Настройки прокси
Такие настройки позволяют существенно ускорить парсинг, однако не всем сайтам подходят: на некоторых настроена защита от такого активного парсинга, некоторые просто не выдерживают и сайт падает — в этих ситуациях придется увеличивать интервал между запросами (обычно до 6-7 секунд) и уменьшать количество потоков (часто до 1).
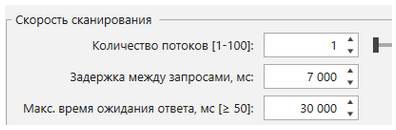
Рисунок 16 — Настройки прокси
Спарсили и экспортировали результаты
Запустили парсинг наших подготовленных урлов. Следим, чтобы сайт не упал; если начинаются 503 коды ответа, то уменьшаем количество потоков и увеличиваем задержку между запросами.
После завершения экспортируем результаты и работаем с ними в таблицах.
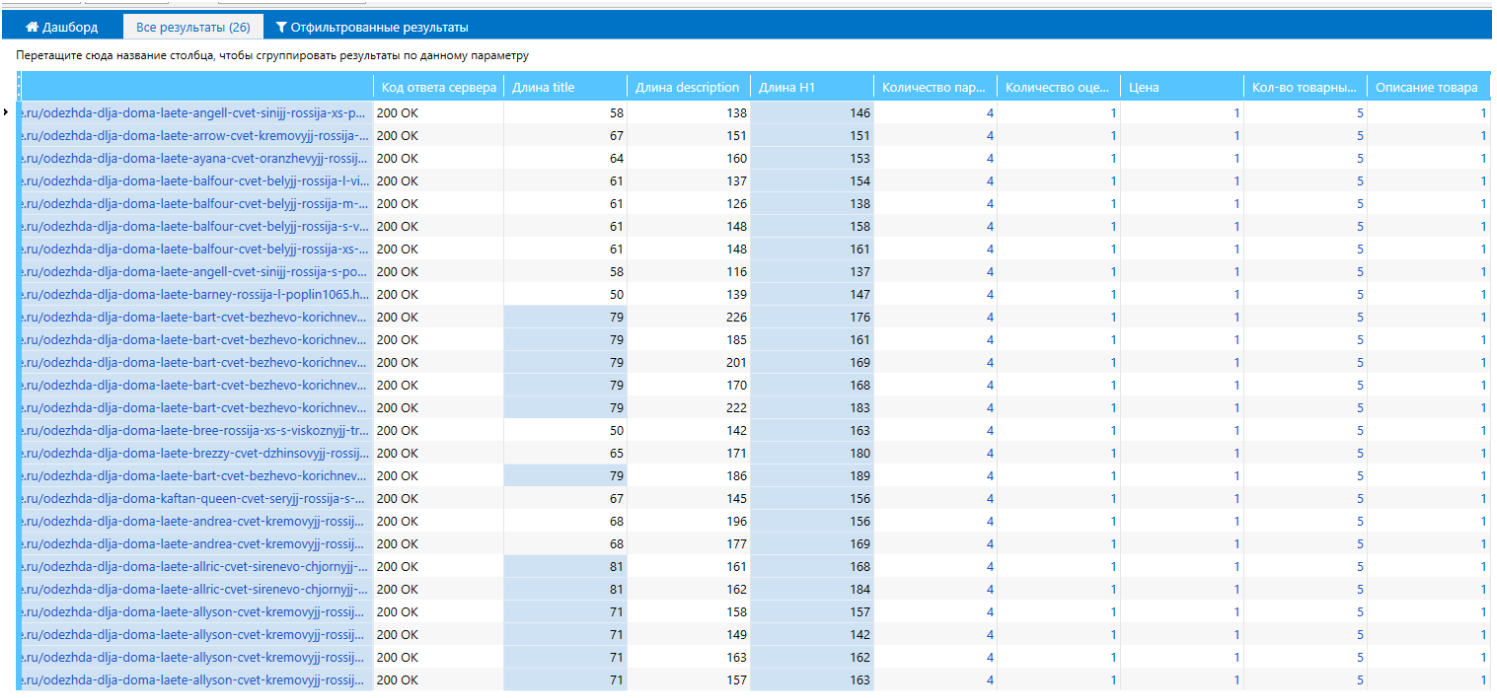

Рисунок 17 — Экспорт результатов
Некоторые результаты надо экспортировать отдельно, например описание товара:

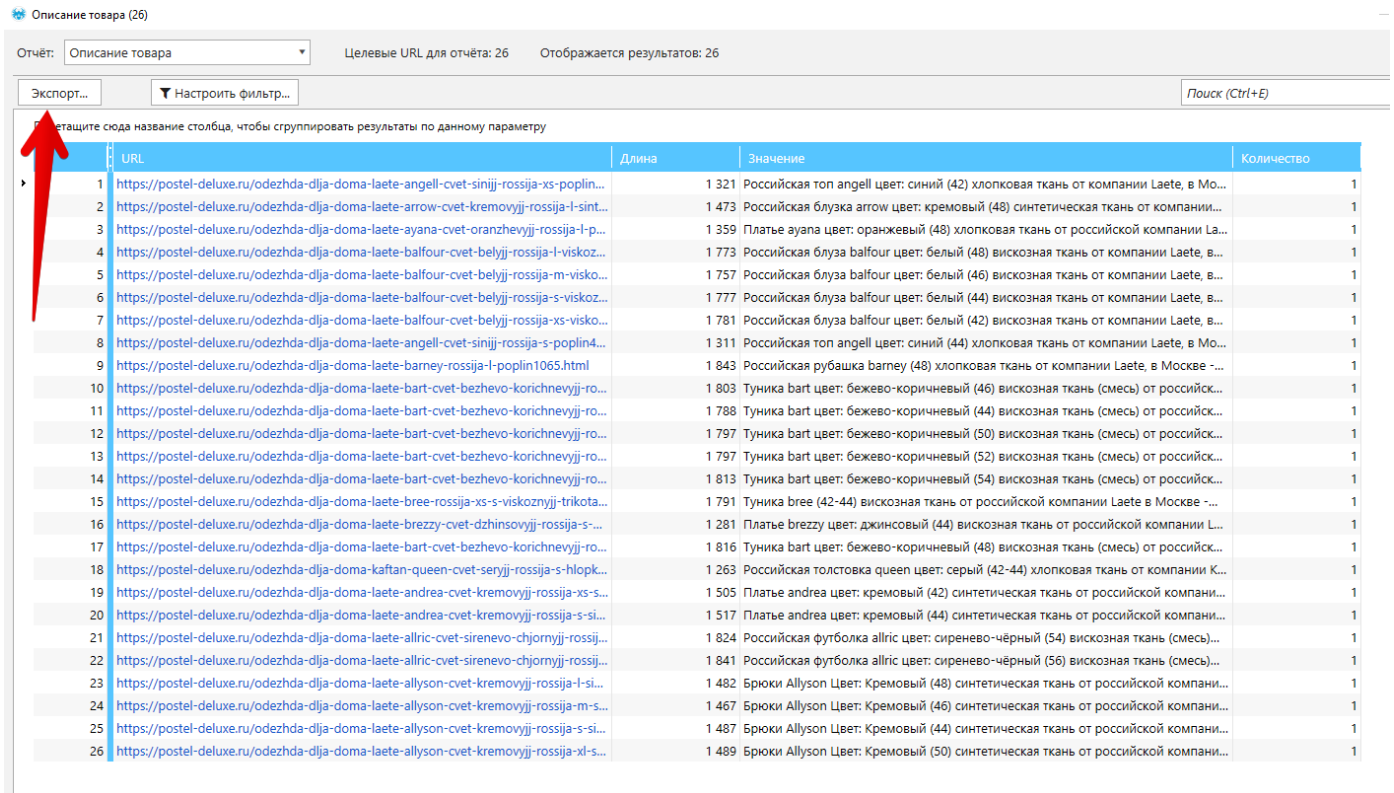
Рисунок 18 — Экспорт отдельных результатов
Посчитали окончательные цифры и занесли в табличку
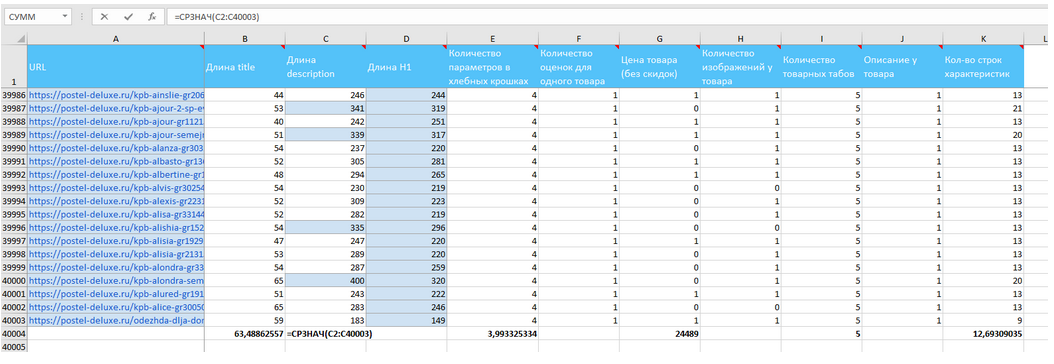
Рисунок 19 — Сводная таблица
Видим, что некоторые колонки достаточно посчитать с помощью срзнач(). Для других, например, для длины текстового описания, придется сделать дополнительную выгрузку и посчитать ее среднее. Иногда также нужны текстовые фильтры:
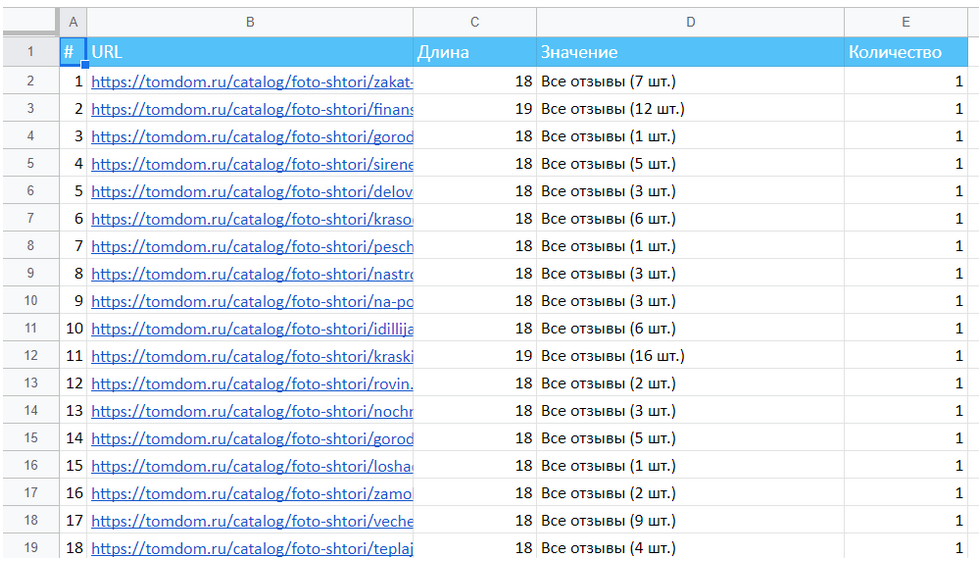
Рисунок 20 — Сводная таблица
Построили графики и описали зависимости, дали рекомендации
Таблица Построение графиков.
На примере нескольких реальных данных парсинга посмотрим, как строить сложные графики в Эксель.
Мы будем строить все графики на основе видимости ТОП3 и ТОП10. Для этого отсортировали конкурентов по убыванию видимости (так диаграмма будет наглядной).
На всех графиках у нас будут присутствовать:
- адреса сайтов — подписи
- видимость ТОП3 и видимость ТОП10 — графики со вспомогательной осью
- другие данные — диаграммы с группировкой
Выделяем нужные диапазоны и выбираем Вставка — Комбинированная диаграмма.
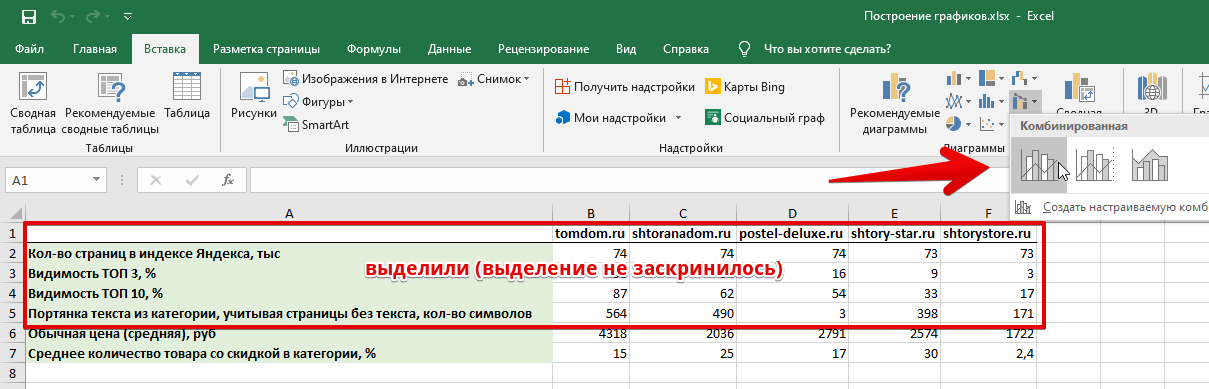
Рисунок 21 — Вставка диаграммы
Сразу выставляем нужный тип диаграммы для каждых значений (ПКМ Изменить тип диаграммы) и вспомогательные оси для видимости. Добавляем метки данных и при необходимости вносим мелкие косметические правки — перетаскиваем цифры, подписываем оси, меняем диапазон осей.
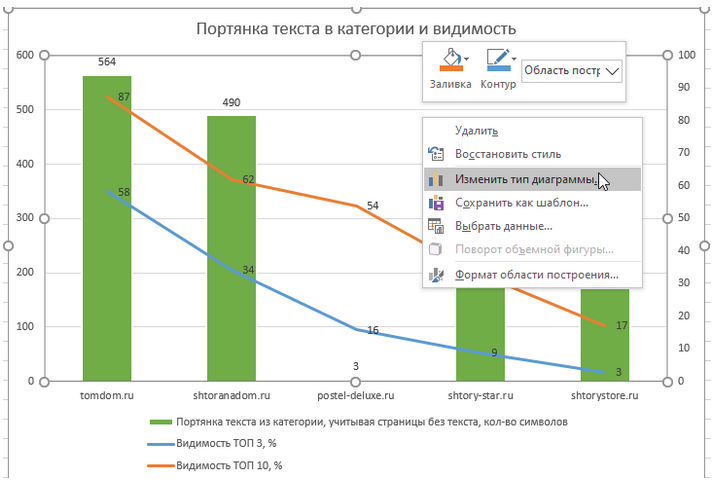

Рисунок 22 — Настройка диаграммы
Составляем диаграммы и описываем их. По результатам даем рекомендации: что добавить, что убрать, где увеличить длину текста и т.д.
Пример реального отчета парсинга сайтов-конкурентов с описанием результатов, рекомендациями и выводами.
Реальные примеры графиков и рекомендаций на их основе:
Благодаря этому графику мы смогли дать ответ на вопрос клиента: “обязательно ли добавлять видео в категории или можно обойтись без этого”. Ответ очевиден: сайты с видео на категориях имеют лучшую видимость, значит, и нашему клиенту нужны видео на категориях, если он претендует на первые позиции в поиске.

Рисунок 23 — Результаты на диаграмме
А на этой диаграмме наглядно показано, что на нашем сайте представлено недостаточно брендов гель-лаков. Если мы хотим улучшить видимость, нужно добавлять новые бренды.
Также здесь видно, что у нас нет перечисления способов оплаты, в то время как все более успешные конкуренты их указали. Следовательно, даем рекомендацию добавить на сайт способы оплаты.
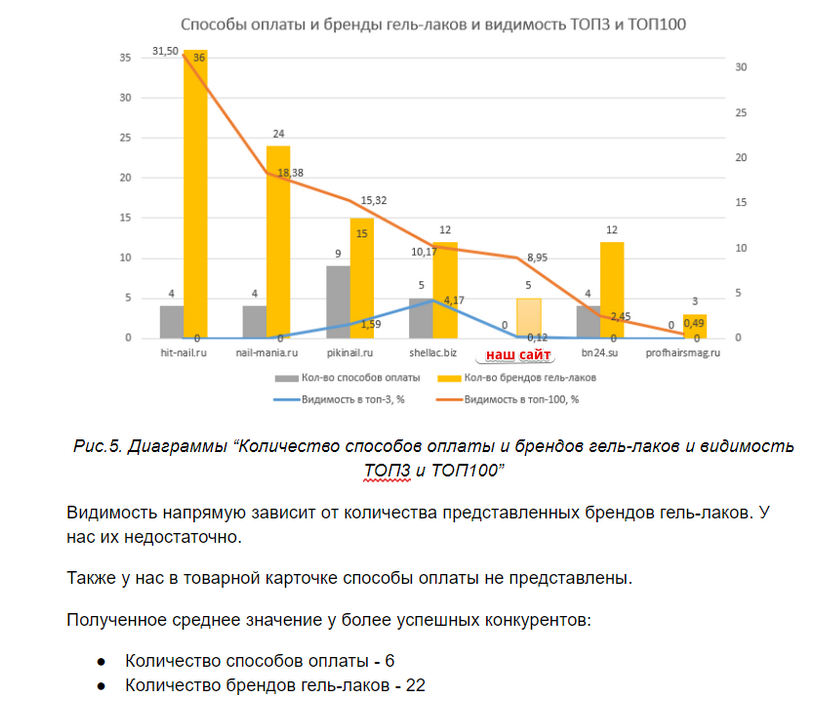
Рисунок 24 — Результаты на диаграмме
Подводим итоги
Аудит коммерческих факторов — это комплексный подход к выявлению совершенно различных и порой неочевидных параметров, которые косвенно или напрямую влияют на ранжирование сайта в вашей нише.
Почему упоминаем именно про нишу и почему нельзя провести проверку один раз и составить общие рекомендации для всех?
Это очень просто. Алгоритмы поисковых систем устроены так, что не существует единых правил, которые бы гарантировали вам высокие позиции. И если ряд общих правил верен почти всегда (например, ваши позиции наверняка понизятся, если на сайт добавить рекламу запрещенной тематики), то для конкретной ниши стоит рассмотреть факторы ранжирования более пристально. То, что отлично сработало, скажем, для автосалонов, может не сработать (или даже ухудшить позиции) для магазина цветов.
Хочется отметить, что данный аудит хорош своей наглядностью: графики сразу демонстрируют, в чем сайт отстает и есть ли вообще зависимость между видимостью и конкретным фактором.
Также такой подход позволяет составить систематизированные рекомендации, выраженные численно: не просто “добавить/убрать/написать..”, а “количество категорий с рейтингом должно быть не меньше 40%”, “средняя длина description категорий должна быть 177 символов, товаров — 182 символа” и т.п.
А если вы запутались или не хотите тратить свое время, обратитесь к нам. По итогам аудита вы получите полный список рекомендаций, развернутый отчет с графиками и пояснениями.
Дисклеймер: с нашей точки зрения, связать математически параметры коммерческих факторов сайтов и их ранжирование в поисковой системе не представляется возможным, так как, помимо количественного фактора, вмешивается качественный. По представленным примерам отчетов вы можете видеть, что мы сравнивали довольно большое количество различных данных и использовали «визуальную оценку» наличия или отсутствия зависимости. Поэтому, кроме общих рекомендаций для владельцев сайтов, ничего более математического в данной ситуации, на наш взгляд, сделать невозможно из-за огромного количества мелочей, которые могут оказывать влияние на конечный результат (позицию в ПС). Однако по опыту предыдущих проектов, это не означает, что наши рекомендации плохие. Наоборот, те из наших клиентов, кто внедрил рекомендации аудита, смогли улучшить видимость и поднять позиции по сравнению с предыдущим временным периодом.
P.S. Друзья, для вашего удобства мы сняли видео, где подробно объясняем и показываем, как выбрать топовых конкурентов по видимости и проанализировать их от и до.
Чтобы первыми узнавать обо всех наших новых материалах, подписывайтесь на наш telegram-канал: t.me/seoantteam
Никакого спама. Только полезная информация по теме SEO.
Ссылки на бесплатные видеоуроки по теме
- Коммерческие факторы ранжирования сайтов
- Общие элементы коммерческих факторов ранжирования сайтов
- Коммерческие факторы для интернет-магазинов
- Коммерческие факторы для сайтов услуг

